들어가며
이 글은 "기초부터 다지는 ElasticSearch 운영 노하우" 박상헌.강진우 지음, 인사이트 2021.을 읽으면서 주요 포인트만 기록한 것입니다.
빠르게 개념을 잡거나, 아는 것을 정리하기에 좋은 책이었습니다.
엘라스틱서치를 사용하시는 분은 일독 하셔도 좋을 것 같습니다.
- YES24.COM: http://www.yes24.com/Product/Goods/96520155

1장. 준비
도커 환경 준비 (6.8.23 버전)
https://www.elastic.co/guide/en/elasticsearch/reference/6.8/docker.html
docker-compose.yml
version: '3'
services:
es01:
image: docker.elastic.co/elasticsearch/elasticsearch:6.8.23
container_name: es01
environment:
- node.name=es01
- cluster.name=es-docker-cluster
- discovery.zen.ping.unicast.hosts=es02,es03
# - bootstrap.memory_lock=true
#- "ES_JAVA_OPTS=-Xms2g -Xmx2g"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data01:/usr/share/elasticsearch/data
ports:
- 9200:9200
- 9300:9300
networks:
- elastic
es02:
image: docker.elastic.co/elasticsearch/elasticsearch:6.8.23
container_name: es02
environment:
- node.name=es02
- cluster.name=es-docker-cluster
- discovery.zen.ping.unicast.hosts=es01,es03
# - bootstrap.memory_lock=true
#- "ES_JAVA_OPTS=-Xms2g -Xmx2g"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data02:/usr/share/elasticsearch/data
ports:
- 9201:9200
- 9301:9300
networks:
- elastic
es03:
image: docker.elastic.co/elasticsearch/elasticsearch:6.8.23
container_name: es03
environment:
- node.name=es03
- cluster.name=es-docker-cluster
- discovery.zen.ping.unicast.hosts=es01,es02
# - bootstrap.memory_lock=true
#- "ES_JAVA_OPTS=-Xms2g -Xmx2g"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data03:/usr/share/elasticsearch/data
ports:
- 9202:9200
- 9302:9300
networks:
- elastic
kibana:
container_name: kibana
image: docker.elastic.co/kibana/kibana:6.8.23
environment:
SERVER_NAME: kibana
ELASTICSEARCH_HOSTS: http://es01:9200
ports:
- 5601:5601
depends_on:
- es01
- es02
- es03
networks:
- elastic
cerebro:
image: 'lmenezes/cerebro'
container_name: 'cerebro'
ports:
- "9000:9000"
environment:
- "CEREBRO_PORT=9000"
- "ELASTICSEARCH_HOST=http://es01:9200"
networks:
- elastic
volumes:
data01:
driver: local
data02:
driver: local
data03:
driver: local
kibana:
driver: local
networks:
elastic:
driver: bridge(optional) Docker Memory 설정 변경
- 메모리가 많이 필요하니 4~5GB 이상으로 설정한다. docker container가 이 메모리만큼 무조건 할당 받는 것은 아니고, 사용할 수 있는 메모리의 상한선을 지정하는 것이다.
- 메모리 부족 케이스: 메모리 할당 제한에 도달해서 docker container가 강제종료 된 경우에는
docker ps -a로 확인하면Exit(137)로 표시된다.
- 메모리 부족 케이스: 메모리 할당 제한에 도달해서 docker container가 강제종료 된 경우에는
- Docker Desktop: Preferences > Resources > Advanced
- 변경한 후
Apply & Restart버튼을 눌러 적용한다.
기동 & 종료
❯ docker-compose up -d
❯ docker-compose down -v # volume까지 삭제
❯ docker-compose rm접속
- Elasticsearch: http://localhost:9200
- Kibana: http://localhost:5601
- Cerebro: http://localhost:9000
- 실행하면 표시되는 UI의 Node address에
http://es01:9200를 입력
- 실행하면 표시되는 UI의 Node address에
2장. Elasticsearch 기본 동작
문서 색인하기
curl -X PUT "localhost:9200/user/_doc/1?pretty" -H 'Content-Type: application/json' -d'
{
"username": "harry.jang"
}
'# (result)
{
"_index" : "user",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}PUT: 새로운 문서 입력user: 문서를 색인할 인덱스 이름_doc: 문서의 타입(_doc으로 고정됨)1: 문서의 ID
색인이 일어나는 과정
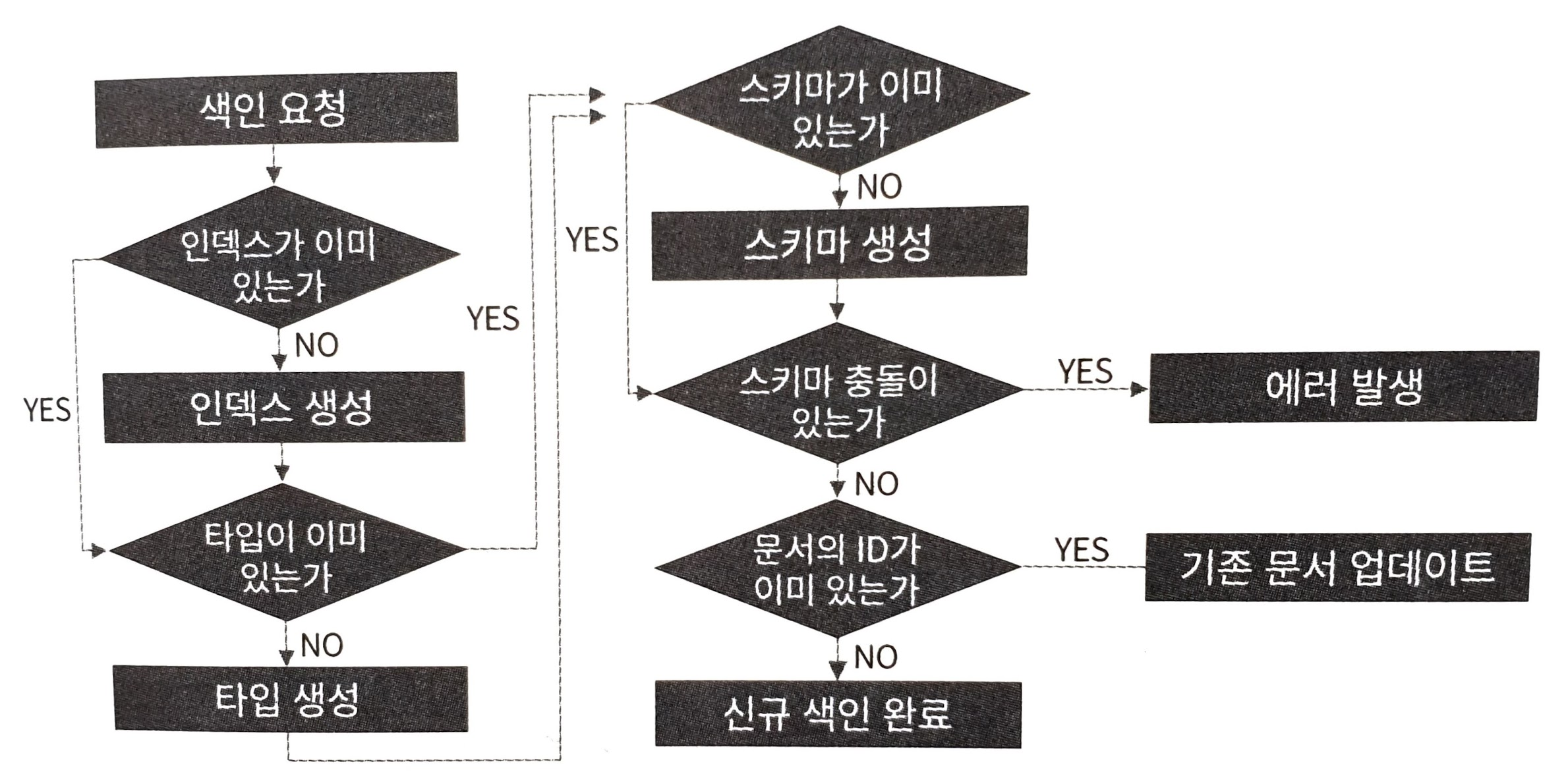
문서 조회하기
❯ curl -X GET "localhost:9200/user/_doc/1?pretty"
# (result)
{
"_index" : "user",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"username" : "harry.jang"
}
}_index: 인덱스 이름_type: 타입 이름_id: 문서 id_source: 문서의 내용 (JSON)
문서 삭제하기
❯ curl -X DELETE "localhost:9200/user/_doc/1?pretty"
# (result)
{
"_index" : "user",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "deleted",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 4,
"_primary_term" : 1
}result:deleted정상적으로 삭제됨
삭제된 문서 조회하기
❯ curl -X DELETE "localhost:9200/user/_doc/1?pretty"
# (result)
{
"_index" : "user",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "not_found",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 5,
"_primary_term" : 1
}문서 검색하기
books.json
https://github.com/benjamin-btn/ES-SampleData/blob/master/books.json
{"index":{"_id":"1"}}
{ "title" : "Kubernetes: Up and Running", "reviews": 10, "rating": 5.0, "authors": "Joe Beda, Brendan Burns, Kelsey Hightower", "topics": "Kubernetes", "publisher": "O'Reilly Media, Inc.", "ISBN": "9781491935675", "release_date": "2017/09/03", "description" : "What separates the traditional enterprise from the likes of Amazon, Netflix, and Etsy? Those companies have refined the art of cloud native development to maintain their competitive edge and stay well ahead of the competition. This practical guide shows Java/JVM developers how to build better software, faster, using Spring Boot, Spring Cloud, and Cloud Foundry." }
{"index":{"_id":"2"}}
{ "title" : "Cloud Native Java", "reviews": 33, "rating": 4.3, "authors": "Kenny Bastani, Josh Long", "topics": "Java", "publisher": "O'Reilly Media, Inc.", "ISBN": "9781449374648", "release_date": "2017/08/04", "description" : "What separates the traditional enterprise from the likes of Amazon, Netflix, and Etsy? Those companies have refined the art of cloud native development to maintain their competitive edge and stay well ahead of the competition. This practical guide shows Java/JVM developers how to build better software, faster, using Spring Boot, Spring Cloud, and Cloud Foundry." }
{"index":{"_id":"3"}}
{ "title" : "Learning Chef", "reviews": 20, "rating": 4.2, "authors": "Mischa Taylor, Seth Vargo", "topics": "Chef", "publisher": "O'Reilly Media, Inc.", "ISBN": "9781491944936", "release_date": "2014/11/08", "description" : "Get a hands-on introduction to the Chef, the configuration management tool for solving operations issues in enterprises large and small. Ideal for developers and sysadmins new to configuration management, this guide shows you to automate the packaging and delivery of applications in your infrastructure. You’ll be able to build (or rebuild) your infrastructure’s application stack in minutes or hours, rather than days or weeks." }
{"index":{"_id":"4"}}
{ "title" : "Elasticsearch Indexing", "reviews": 24, "rating": 4.6, "authors": "Hüseyin Akdoğan", "topics": "ElasticSearch", "publisher": "Packt Publishing", "ISBN": "9781783987023", "release_date": "2015/12/22", "description" : "Improve search experiences with ElasticSearch’s powerful indexing functionality – learn how with this practical ElasticSearch tutorial, packed with tips!" }
{"index":{"_id":"5"}}
{ "title" : "Hadoop: The Definitive Guide, 4th Edition", "reviews": 15, "rating": 4.9, "authors": "Tom White", "topics": "Hadoop", "publisher": "O'Reilly Media, Inc.", "ISBN": "9781491901632", "release_date": "2015/04/14", "description" : "Get ready to unlock the power of your data. With the fourth edition of this comprehensive guide, you’ll learn how to build and maintain reliable, scalable, distributed systems with Apache Hadoop. This book is ideal for programmers looking to analyze datasets of any size, and for administrators who want to set up and run Hadoop clusters." }
{"index":{"_id":"6"}}
{ "title": "Getting Started with Impala", "reviews": 18, "rating": 3.8, "authors": "John Russell", "topics": "Impala", "publisher": "O'Reilly Media, Inc.", "ISBN": "9781491905777", "release_date": "2014/09/14", "description" : "Learn how to write, tune, and port SQL queries and other statements for a Big Data environment, using Impala—the massively parallel processing SQL query engine for Apache Hadoop. The best practices in this practical guide help you design database schemas that not only interoperate with other Hadoop components, and are convenient for administers to manage and monitor, but also accommodate future expansion in data size and evolution of software capabilities. Ideal for database developers and business analysts, the latest revision covers analytics functions, complex types, incremental statistics, subqueries, and submission to the Apache incubator." }
{"index":{"_id":"7"}}
{ "title": "NGINX High Performance", "reviews": 21, "rating": 4.7, "authors": "Rahul Sharma", "topics": "Nginx", "publisher": "Packt Publishing", "ISBN": "9781785281839", "release_date": "2015/07/29", "description": "Optimize NGINX for high-performance, scalable web applications" }
{"index":{"_id":"8"}}
{ "title": "Mastering NGINX - Second Edition", "reviews": 6, "rating": 3.6, "authors": "Dimitri Aivaliotis", "topics": "Nginx", "publisher": "Packt Publishing", "ISBN": "9781782173311", "release_date": "2016/07/28", "description": "An in-depth guide to configuring NGINX for your everyday server needs" }
{"index":{"_id":"9"}}
{ "title" : "Linux Kernel Development, Third Edition", "reviews": 3, "rating": 4.0, "authors": "Robert Love", "topics": "Linux", "publisher": "Addison-Wesley Professional", "ISBN": "9780672329463", "release_date": "2010/06/09", "description" : "Linux Kernel Development details the design and implementation of the Linux kernel, presenting the content in a manner that is beneficial to those writing and developing kernel code, as well as to programmers seeking to better understand the operating system and become more efficient and productive in their coding." }
{"index":{"_id":"10"}}
{ "title" : "Linux Kernel Development, Second Edition", "reviews": 29, "rating": 5.0, "authors": "Robert Love", "topics": "Linux", "publisher": "Sams", "ISBN": "9780672327209", "release_date": "2005/01/01", "description" : "The Linux kernel is one of the most important and far-reaching open-source projects. That is why Novell Press is excited to bring you the second edition of Linux Kernel Development, Robert Love's widely acclaimed insider's look at the Linux kernel. This authoritative, practical guide helps developers better understand the Linux kernel through updated coverage of all the major subsystems as well as new features associated with the Linux 2.6 kernel. You'll be able to take an in-depth look at Linux kernel from both a theoretical and an applied perspective as you cover a wide range of topics, including algorithms, system call interface, paging strategies and kernel synchronization. Get the top information right from the source in Linux Kernel Development." }테스트 데이터 색인하기
❯ curl -H "Content-Type: application/json" -X POST "localhost:9200/books/_doc/_bulk?pretty&refresh" --data-binary "@books.json"전체 문서를 검색
q: query*: 모든 단어
❯ curl -X GET "localhost:9200/books/_search?q=*&pretty"
# (result)
{
"took" : 39, # 소요 시간
"timed_out" : false,
"_shards" : {
"total" : 5, # 검색에 참여한 샤드의 수
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 10, # 검색 결과 수
"max_score" : 1.0,
"hits" : [
{
"_index" : "books",
"_type" : "_doc",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"title" : "Hadoop: The Definitive Guide, 4th Edition",
"reviews" : 15,
"rating" : 4.9,
"authors" : "Tom White",
"topics" : "Hadoop",
"publisher" : "O'Reilly Media, Inc.",
"ISBN" : "9781491901632",
"release_date" : "2015/04/14",
"description" : "Get ready to ..."
}
},
...특정 단어를 포함하는 문서를 검색
❯ curl -X GET "localhost:9200/books/_search?q=elasticsearch&pretty"
# (result)
{
"took" : 23,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 1.3591961,
"hits" : [
{
"_index" : "books",
"_type" : "_doc",
"_id" : "4",
"_score" : 1.3591961,
"_source" : {
"title" : "Elasticsearch Indexing",
"reviews" : 24,
"rating" : 4.6,
"authors" : "Hüseyin Akdoğan",
"topics" : "ElasticSearch",
"publisher" : "Packt Publishing",
"ISBN" : "9781783987023",
"release_date" : "2015/12/22",
"description" : "Improve search experiences with ElasticSearch’s powerful indexing functionality – learn how with this practical ElasticSearch tutorial, packed with tips!"
}
}
]
}
}rating 프로퍼티 값이 5.0인 문서를 검색
❯ curl -X GET "localhost:9200/books/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"rating": 5.0
}
}
}
'
# (result)
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 2,
"max_score" : 1.0,
"hits" : [
{
"_index" : "books",
"_type" : "_doc",
"_id" : "10",
"_score" : 1.0,
"_source" : {
"title" : "Linux Kernel Development, Second Edition",
"reviews" : 29,
"rating" : 5.0,
"authors" : "Robert Love",
"topics" : "Linux",
"publisher" : "Sams",
"ISBN" : "9780672327209",
"release_date" : "2005/01/01",
"description" : "..."
}
},
{
"_index" : "books",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"title" : "Kubernetes: Up and Running",
"reviews" : 10,
"rating" : 5.0,
"authors" : "Joe Beda, Brendan Burns, Kelsey Hightower",
"topics" : "Kubernetes",
"publisher" : "O'Reilly Media, Inc.",
"ISBN" : "9781491935675",
"release_date" : "2017/09/03",
"description" : "..."
}
}
]
}
}reviews 프로퍼티의 값이 10 이상인 문서를 검색
❯ curl -X GET "localhost:9200/books/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"bool": {
"must": { "match_all": {} },
"filter": {
"range": {
"reviews": {
"gte": 10
}
}
}
}
}
}
'
# (result)
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 8,
"max_score" : 1.0,
"hits" : [
{
"_index" : "books",
"_type" : "_doc",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"title" : "Hadoop: The Definitive Guide, 4th Edition",
"reviews" : 15,
"rating" : 4.9,
"authors" : "Tom White",
"topics" : "Hadoop",
"publisher" : "O'Reilly Media, Inc.",
"ISBN" : "9781491901632",
"release_date" : "2015/04/14",
"description" : "..."
}
},
{
"_index" : "books",
"_type" : "_doc",
"_id" : "10",
"_score" : 1.0,
"_source" : {
"title" : "Linux Kernel Development, Second Edition",
"reviews" : 29,
"rating" : 5.0,
"authors" : "Robert Love",
"topics" : "Linux",
"publisher" : "Sams",
...3장. Elasticsearch 모니터링
Head
- https://github.com/mobz/elasticsearch-head
- 책에서 다루고 있지만 현재 업데이트가 되지 않고 있다.
설치
❯ docker run -d -i -p 9100:9100 --name ubuntu ubuntu:18.04
❯ docker exec -it ubuntu /bin/bash
(docker)
$ apt-get update; apt-get install -y npm; apt-get install -y git
$ git clone https://github.com/mobz/elasticsearch-head.git
$ cd elasticsearch-head/
elasticsearch-head$ npm install
elasticsearch-head$ npm run start
# (result)
> elasticsearch-head@0.0.0 start /elasticsearch-head
> grunt server
(node:4704) ExperimentalWarning: The http2 module is an experimental API.
Running "connect:server" (connect) task
Waiting forever...
Started connect web server on http://localhost:9100
(cursor)ES 노드의 CORS 설정
Head를 통해서 Elasticsearch에 접속하려면 ES 노드에 CORS 허용을 설정해 주어야 한다.
❯ docker exec -it es01 /bin/bash
(docker)
elasticsearch$ cd config
elasticsearch$ vi elasticsearch.yml
---------------------------------------------
...
http.cors.enabled: true
http.cors.allow-origin: "*"
---------------------------------------------
elasticsearch$ exit
❯ docker-compose restart elasticsearch
# (result)
[+] Running 1/1
⠿ Container es01 Started접속
Cerebro (추천)
Kibana
Monitoring 활성화
Monitoring 탭에서 Turn on monitoring 버튼을 클릭한다.
4장. Elasticsearch 기본 개념
노드의 역할
| 역할 | 설명 |
| 마스터(Master-eligible) | 클러스터 구성에서 중심이 되는 노드. 클러스터의 상태 등 메타데이터를 관리한다. |
| 데이터(Data) | 사용자의 문서를 실제로 저장하는 노드 |
| 인제스트(Ingest) | 사용자의 문서가 저장되기 전 문서 내용을 전처리하는 노드 |
| 코디네이트(Coordinate) | 사용자의 요청을 데이터 노드로 전달하고, 다시 데이터 노드로 부터 결과를 취합하는 노드 |
마스터 노드
- 클러스터의 메타데이터를 관리한다.
- 한 대 이상으로 구성. 1대만 Active이고 나머지는 Stand-by 상태이다.
- 클러스터 내의 모든 노드는 자신의 상태, 성능 정보, 샤드 정보 등을 마스터 노드에 알린다. 마스터 노드는 이런 정보를 수집하고 관리한다.
데이터 노드
- 사용자가 색인한 문서를 저장
- 검색 요청을 처리해서 결과를 반환
- 자신이 받은 요청 중 다른 데이터 노드에서 처리해야 할 요청이면, 해당 데이터 노드에 요청을 전달
- 인제스트 노드
- 색인해야 하는 문서의 내용 중 변환이 필요한 부분에 대한 사전 처리
- 데이터 노드에 저장하기 전에 특정 프로퍼티의 값을 가공해야 할 경우 등
코디네이트 노드
- 실제 데이터를 저장하거나 처리하지는 않음
- 사용자의 모든 요청(색인/검색)을 데이터 노드에 전달
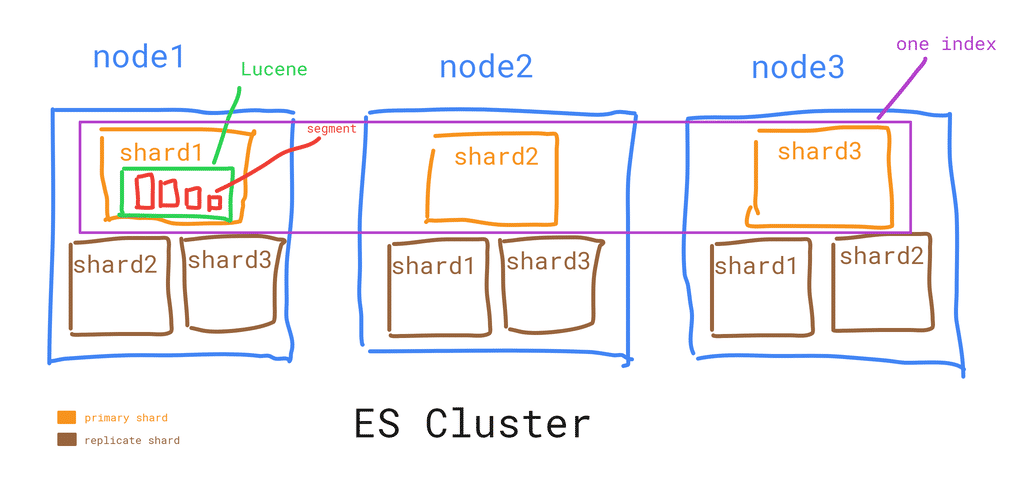
인덱스와 타입
- 인덱스(index): 사용자의 데이터(문서)가 저장되는 논리적인 공간 - RDBMS에서 데이터베이스에 해당
- 타입(type): 인덱스 안의 데이터를 유형에 따라 논리적으로 나눠 놓은 공간 - RDBMS에서 테이블에 해당
- ES 6.x 버전 부터는 인덱스에 하나의 타입만 허용하므로, 타입은 의미가 없어졌고, 인덱스는 RDBMS에서의 테이블에 해당하게 되었음
- 보통
_doc을 타입명으로 사용(권고). 향후_doc으로 고정될 예정.
- 문서는 JSON 형태이며, property와 value로 구성됨. property가 object를 가지는 중첩 구조가 가능하나 권장되지는 않음.
샤드와 세그먼트
- 샤드: 인덱스에 색인되는 문서들이 저장되는 논리적인 공간
- 세그먼트: 샤드의 데이터들이 저장되는 물리적인 파일
- 따라서 인덱스에 저장되는 문서는 세그먼트에 나뉘어 저장됨
샤드
- 하나의 인덱스는 1개 이상의 샤드로 구성됨
- 하나의 샤드는 1개 이상의 세그먼트로 구성됨
- 샤드는 데이터 노드에 할당되며, 저장공간의 수평적 확장을 가능하게 함
- 샤드는 원본인 프라이머리 샤드와 복제본인 레플리카 샤드로 구성됨 - 데이터 안정성 향상(fault tolerence)
- 프라이머리 샤드의 개수는 인덱스 생성 시점에 결정하고 이후에 변경 불가
세그먼트
- 색인된 문서가 저장되는 물리적인 파일
- 준 실시간 검색을 지원: 문서 색인 -> 시스템 메모리의 버퍼 캐시에 저장 (검색 불가능한 상태) -> refresh(flush, default 1초 마다) -> 디스크의 세그먼트에 저장 (검색 가능)
- 불변(immutable)의 특성을 가짐 - 기존에 기록한 데이터는 변경되지 않음
- 문서에 대한 업데이트: 새로운 문서를 색인한 후 기존 문서를
deleted로 마킹함 - 문서에 대한 삭제: 기존 문서를
deleted로 마킹함
- 문서에 대한 업데이트: 새로운 문서를 색인한 후 기존 문서를
- 세그먼트 병합(merge): 시간이 지날 수록 작은 세그먼트가 늘어나서 느려지기 때문에, 백그라운드에서 여러 개의 작은 세그먼트를 병합(merge)하여 새로운 하나의 세그먼트로 만드는 작업이 진행됨. 이 때
deleted로 마킹된 문서가 실제로 삭제됨(merge 대상에서 제외됨).
프라이머리 샤드와 레플리카 샤드
프라이머리 샤드
- 인덱스는 1개 이상의 샤드로 구성되며, 인덱스에 저장되는 문서는 이 샤드들에 나뉘어 저장된다. 인덱스의 문서가 저장되는 원본 샤드를 프라이머리 샤드라고 한다.
- 인덱스를 만들 때 프라이머리 샤드의 개수를 필수로 지정해야 한다.
number_of_shards로 지정하며, default는 5개 이다. - 샤드 번호는 0부터 시작한다. 샤드 개수가 3이라면 샤드 번호는 0, 1, 2로 생성된다.
- 샤드들은 클러스터를 구성하는 노드들에 분산된다.
- N개의 프라이머리 샤드가 있을 때 색인된 문서는 해시 값을 MOD 연산하여 저장될 샤드 번호가 결정된다.
- 저장될 샤드 번호 = hash(문서id) % 프라이머리 샤드 개수 N
- 인덱스에 저장된 문서는 이미 샤드 수에 기반해서 저장되어 있기 때문에, 인덱스 생성 후에는 프라이머리 샤드 개수를 변경할 수 없다.
레플리카 샤드
- 프라이머리 샤드에 장애가 발생하거나 유실될 때를 대비하여 복제본인 레플리카 샤드를 가질 수 있다.
- 동일한 번호를 가지는 프라이머리 샤드와 레플리카 샤드는 동일한 데이터 노드에 할당되지 않는다. 따라서 샤드 오류시 데이터의 안정성을 확보할 수 있다.
- 하나의 노드로 구성된 클러스터에서는 레플리카 샤드를 둘 수 없다.
- 레플리카 수는
number_of_replicas로 지정하며, default로 1이다. - 레플리카 수는 변경(증가/감소) 가능하다. 0으로 지정하면 레플리카 샤드가 모두 삭제된다.
- 레플리카 샤드는 프라이머리 샤드와 동일한 문서를 가지고 있기 때문에 검색 요청을 처리할 수 있으며, 레플리카 수를 늘려서 검색 성능을 향상시킬 수 있다.
매핑
- RDBMS에서의 테이블 스키마와 유사하다.
- 문서에 어떤 프로퍼티와 어떤 타입의 값을 가질지 정의한 것이다.
- 인덱스의 매핑 정보를 미리 정의하지 않으면 자동으로 적절한(?) 매핑이 생성된다. 하지만 실무에서는 권장되지 않는다.
- 일반적으로 템플릿을 정의해 두고, 인덱스가 생성될 때 매핑이 적용되도록 한다(6장). 템플릿에는 샤드 수, 레플리카 수, 매핑, alias를 정의한다.
- 인덱스의 매핑 정보는 변경할 수 없다. 운영 중인 인덱스의 매핑 정보를 변경해야 할 필요가 생기면, 템플릿의 매핑 정보를 변경한 후 reindex api를 사용하여 인덱스를 복제 생성하는 방식을 많이 사용한다.
매핑 정보 확인
curl -X GET "localhost:9200/books/_mapping?pretty"
# (result)
{
"books" : {
"mappings" : {
"_doc" : { # _doc 타입
"properties" : { # 프로퍼티
"ISBN" : { # 프로퍼티 이름
"type" : "text", # text 타입
"fields" : {
"keyword" : {
"type" : "keyword", # keyword 타입이 추가됨
"ignore_above" : 256
}
}
},
"authors" : {
"type" : "text", # text 타입
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
...,
"rating" : {
"type" : "float" # float 타입
},
"release_date" : {
"type" : "date", # date 타입
"format" : "yyyy/MM/dd HH:mm:ss||yyyy/MM/dd||epoch_millis"
},
"reviews" : {
"type" : "long" # long 타입
},
"title" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"topics" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
}매핑정보와 함께 인덱스 생성하기
curl -X PUT "localhost:9200/movie?pretty" -H 'Content-Type: application/json' -d'
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
},
"mappings": {
...
}
}
'매핑 타입 종류
| 코어 데이터 타입 | 설명 | 종류 |
| String | 문자열 데이터 타입 | text, keyword |
| Numeric | 숫자형 데이터 타입 | long, integer, short, byte, double, float, half_float, scaled_float |
| Date | 날짜형 데이터 타입 | date |
| Boolean | 불 데이터 타입 | boolean |
| Binary | 바이너리 데이터 타입 | binary |
| Range | 범위 데이터 타입 | integer_range, float_range, long_range, double_range, date_range |
5장. 클러스터 구축하기
환경 부분의 docker-compose.yml을 참고한다.
6장. 클러스터 운영하기
버전 업그레이드
- Full Cluster Restart
- 모든 노드를 동시에 재시작
- 다운 타임 필요
- 빠르고 쉬움
- Rolling Restart
- 노드를 한 대씩 순차적으로 재시작
- 업그레이드, 설정 변경 등에도 활용
- 다운 타임 없음
- 노드가 많은 경우 시간이 오래 걸리고 작업이 복잡
- 노드가 내려갈 경우 다른 노드에 샤드 재분배가 발생하지 않도록 샤드 할당 설정을 disabled 시킨 상태에서 작업
persistent.cluster.routing.allocation.enabled:none- api: p.149 코드 6.1 참조.
curl -X PUT "localhost:9200/_cluster/settings?pretty" ...
인덱스의 설정 변경
레플리카 샤드 수 변경하기
❯ curl -X PUT "localhost:9200/books/_settings?pretty" -H 'Content-Type: application/json' -d'
{
"index.number_of_replicas": 0
}
'설정을 다수의 인덱스에 적용하기
모든 인덱스에 적용
특정 인덱스 이름 대신 _all로 지정하면 모든 인덱스에 적용된다.
❯ curl -X PUT "localhost:9200/_all/_settings?pretty" -H 'Content-Type: application/json' -d'
{
"index.number_of_replicas": 0
}
'인덱스 패턴으로 일부 인덱스에 적용
특정 인덱스 이름 대신 와일드 카드를 사용할 수 있다.
user*:user로 시작하는 모든 인덱스*-2022.01.01: 2022년 1월 1일에 생성된 모든 인덱스
자주 사용되는 인덱스 API
| API | 설명 |
| open/close | 인덱스를 open/close |
| aliases | 인덱스에 별칭 부여 |
| rollover | 인덱스를 새로운 인덱스로 분기 |
| refresh | 문서를 세그먼트에 저장하는 주기를 설정 |
| forcemerge | 샤드 내의 세그먼트를 병합 |
| reindex | 인덱스 복제(마이그레이션) |
open/close API
- 인덱스를 사용 가능한 상태로 혹은 사용 불가능한 상태로 변경한다.
- 인덱스를 새로 만들면 색인과 검색이 가능한
open상태가 된다. close상태로 변경하면 색인과 검색을 할 수 없게 된다.- API 상세: p.180. 코드 6.27 참조.
/{index}/_open or _close
aliases API
- 인덱스에 별칭을 부여한다.
- 클라이언트는 인덱스를 이름이나 별칭으로 접근(색인/검색)할 수 있다.
- 별칭 하나에는 여러 개의 인덱스를 매핑(연결)할 수 있다. 이 경우 별칭을 사용하여 색인할 수는 없으며 검색만 가능하다.
- 아래의 예는
articles라는 별칭으로articles-2020,articles-2021,articles-2022인덱스를 조회할 수 있게 해준다.
❯ curl -X POST "localhost:9200/_aliases?pretty" -H 'Content-Type: application/json' -d'
{
"actions": [
{ "add": { "index": "articles-2020", "alias": "articles" } },
{ "add": { "indices": ["articles-2021", "articles-2022"], "alias": "articles" } },
{ "add": { "index": "articles-201*", "alias": "old_articles" } }
]
}
'rollover API
- 인덱스가 특정 조건을 만족하면 인덱스를 새로 만들고, 새로 생성된 인덱스로 색인/검색 요청을 받게 해준다. 조건을 만족하지 않으면 작업이 수행되지 않는다.
- 대상 인덱스는 aliases API를 사용하여 별칭 설정이 되어 있어야 한다.
- 별칭에 대해 rollover API를 호출하면, 새로운 인덱스가 만들어져서 별칭에 연결되고, 기존 인덱스는 별칭에서 제거된다.
- rollover condition은 3가지를 조합하여 지정할 수 있으며, 하나만 만족해도 롤로버한다.
max_age: 인덱스가 생성된 시각으로 부터 경과. 예) 7dmax_docs: 인덱스의 문서 건수. 예) 50000max_size: 인덱스의 프라이머리 샤드 크기. 예) 5gb
- API 상세: p.186 참조.
refresh API
- refresh_interval 설정과 상관없이 메모리 버퍼 캐시에 있는 문서들을 즉시 세그먼트에 저장하여 검색 가능한 상태로 만들어준다.
- refresh에 대한 것은 p.370. "10.3 refresh_interval 변경하기" 참조
- API 상세: p.191 참조.
forcemerge API
- 인덱스의 샤드를 구성하는 세그먼트들을 강제로 병합하여 최대 n개의 세그먼트로 만든다.
max_num_segments: 샤드 내의 세그먼트들을 최대 몇 개의 세그먼트로 병합할지 지정
- 디스크 I/O를 많이 일으켜 성능이 저하될 수 있기 때문에 색인이 발생하는 인덱스에는 사용하지 않는 것이 좋다.
- 세그먼트 수가 줄어들기 때문에 디스크 사용량을 줄일 수 있고, 검색 성능도 향상시킬 수 있다.
- API 상세: p.191 참조.
reindex API
- 인덱스를 복제(마이그레이션) 한다.
- 주로 index의 analyzer를 변경할 때 사용하며(새로 색인을 해야 하기 때문), 원본 클러스터로 부터 목적지 클러스터로 인덱스를 복사할 때도 사용된다.
❯ curl -X POST "localhost:9200/_reindex?pretty" -H 'Content-Type: application/json' -d'
{
"source": {
"index": "books" # 원본 인덱스
},
"dest": {
"index": "new_books" # 목적지 인덱스
}
}
'
# (result)
{
"took" : 317,
"timed_out" : false,
"total" : 10, # 10개 문서
"updated" : 0,
"created" : 10,
"deleted" : 0,
"batches" : 1,
"version_conflicts" : 0,
"noops" : 0,
"retries" : {
"bulk" : 0,
"search" : 0
},
"throttled_millis" : 0,
"requests_per_second" : -1.0,
"throttled_until_millis" : 0,
"failures" : [ ]
}
템플릿 활용하기
인덱스를 생성할 때 마다 동일한 설정이나 매핑 정보를 지정할 필요가 있는 경우에 사용한다. 새로운 인덱스가 생성될 때 템플릿에 지정된 인덱스 패턴과 일치하면 해당 템플릿의 정보로 인덱스가 만들어진다.
템플릿을 사용하여 정의할 수 있는 항목들
| 항목 | 설명 |
| settings | 인덱스에 대한 설정 정보(샤드 수, 레플리카 수) |
| mappings | 인덱스의 매핑 정보 |
| aliases | 인덱스의 alias 정보 |
템플릿 생성
❯ curl -X PUT "localhost:9200/_template/mytemplate?pretty" -H 'Content-Type: application/json' -d'
{
"index_patterns": [ "test*" ],
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
},
"mappings": {
"_doc": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
}
}
}
},
"aliases": {
"mytests": {}
}
}
'
# (result)
{
"acknowledged" : true
}템플릿 조회
❯ curl -X GET "localhost:9200/_template/mytemplate?pretty"
# (result)
{
"mytemplate" : {
"order" : 0,
"index_patterns" : [
"test*"
],
"settings" : {
"index" : {
"number_of_shards" : "3",
"number_of_replicas" : "1"
}
},
"mappings" : {
"_doc" : {
"properties" : {
"name" : {
"type" : "text"
},
"age" : {
"type" : "integer"
}
}
}
},
"aliases" : {
"mytests" : { }
}
}
}인덱스 생성시 템플릿 적용
# 인덱스 생성
❯ curl -X PUT "localhost:9200/test-1?pretty"
# (result)
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "test-1"
}
# 인덱스 정보 조회
❯ curl -X GET "localhost:9200/test-1?pretty"
# (result)
{
"test-1" : {
"aliases" : {
"mytests" : { }
},
"mappings" : {
"_doc" : {
"properties" : {
"age" : {
"type" : "integer"
},
"name" : {
"type" : "text"
}
}
}
},
"settings" : {
"index" : {
"creation_date" : "1644741411031",
"number_of_shards" : "3",
"number_of_replicas" : "1",
"uuid" : "DyfSpCM0SOuulSeGl1GeXQ",
"version" : {
"created" : "6082399"
},
"provided_name" : "test-1"
}
}
}
}모든 템플릿의 목록 조회
❯ curl -X GET "localhost:9200/_cat/templates?v"
# (result)
name index_patterns order version
mytemplate [test*] 0
.watches [.watches*] 2147483647
.monitoring-logstash [.monitoring-logstash-6-*] 0 6070299
...7장. 클러스터 성능 모니터링과 최적화
클러스터의 상태 확인하기
_cat/health API
❯ curl "localhost:9200/_cat/health?v"
# (result)
... status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
... green 3 3 34 17 0 0 0 0 - 100.0%| 항목 | 설명 |
| node.total | 전체 노드 수 |
| node.data | 데이터 노드 수 |
| shards | 전체 샤드의 수 |
| pri | 프라이머리 샤드 수 |
| relo | 재배치 중인 샤드 수 |
| init | 초기화 중인 샤드 수 |
| unassign | 어느 노드에도 배치되지 않고 남아 있는 샤드 수 |
| pending_tasks | 큐에 쌓여있는 작업의 수 |
| max_task_wait_time | 큐에 적체된 작업을 시작하는데 걸린 최대 시간 |
| active_shards_percent | 전체 중 정상적인 샤드의 비율 |
클러스터의 status
green/yellow에서는 모든 프라이머리 샤드가 정상 동작하기 때문에 데이터 유실은 발생하지 않는다.
| 값 | 의미 |
| green | 모든 샤드가 정상 동작 |
| yellow | 모든 프라이머리 샤드는 정상 동작. 일부 혹은 모든 레플리카 샤드가 정상 동작하지 않음 |
| red | 일부 혹은 모든 프라이머리/레플리카 샤드가 정상 동작하지 않음 |
노드의 상태와 정보 확인하기
_cat/nodes API
❯ curl "localhost:9200/_cat/nodes?v"
# (result)
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.96.5 30 98 2 0.78 0.46 0.52 mdi - es01
192.168.96.2 38 98 3 0.78 0.46 0.52 mdi * es02
192.168.96.4 25 98 2 0.78 0.46 0.52 mdi - es03| 항목 | 설명 |
| ip | 노드의 IP |
| heap.percent | JVM 힙 메모리 사용률 |
| ram.percent | 노드의 메모리 사용률. 대부분 90% 이상인데, JVM 메모리 외의 나머지는 OS에서 페이지 캐시로 사용하기 때문 |
| cpu | 노드의 CPU 사용률 |
| load_xm | Load Average(1m/5m/15m). CPU의 개수를 초과하면 부하가 높은 상황 |
| node.role | 노드의 역할(멀티 가능) - m: 마스터, d: 데이터, i: 인제스트 |
| master | 현재 클러스터의 마스터 여부 |
| name | elasticsearch.yml에 정의한 node.name |
인덱스의 상태와 정보 확인하기
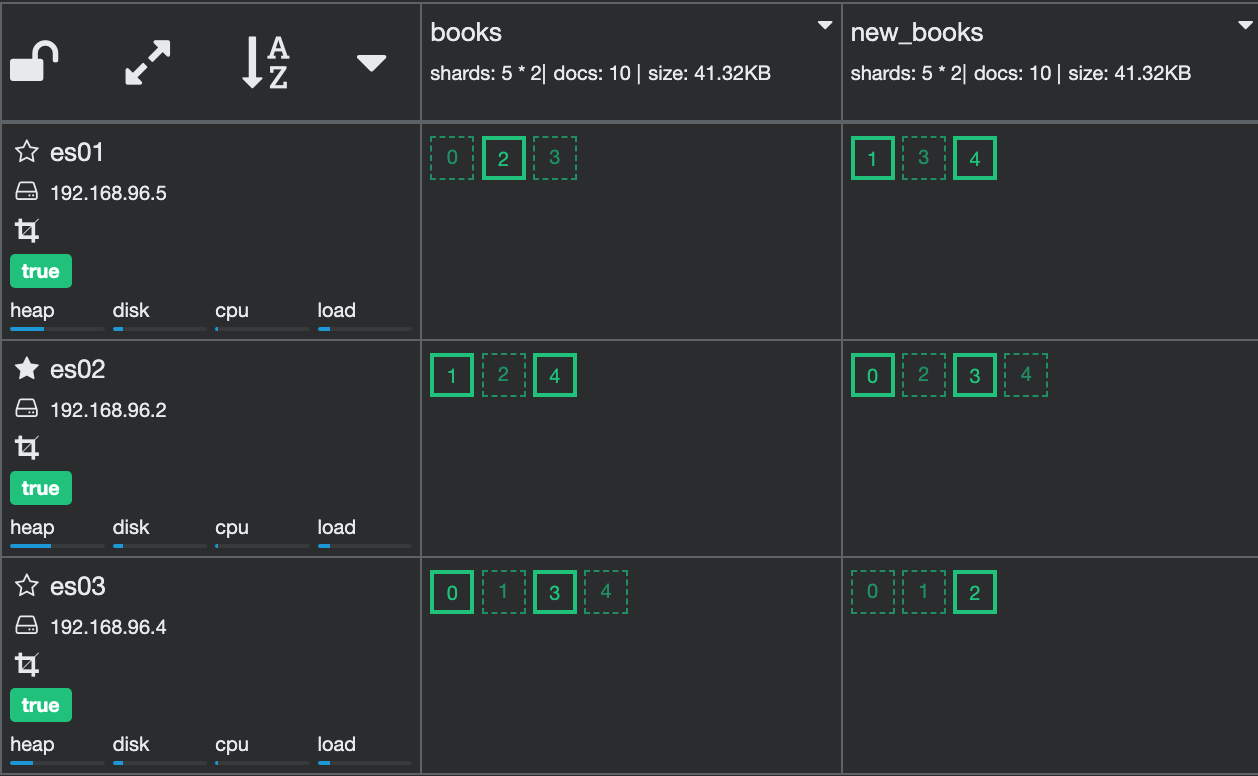
_cat/indices API
❯ curl "localhost:9200/_cat/indices?v"
# (result)
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open new_books g2buAUq8RTiBt15nwjQM7g 5 1 10 0 83.4kb 41.7kb
green open .kibana_task_manager mjAOdrlSQTGdp-AWFYjyPQ 1 1 2 0 25.1kb 12.5kb
green open .monitoring-kibana-6-2022.02.13 YG8t11F_RVqtFxtIItiggA 1 1 819 0 609kb 313.4kb
green open test-1 DyfSpCM0SOuulSeGl1GeXQ 3 1 0 0 1.5kb 783b
green open books xZ-TS_AnTGiLYXe2v1Fa_w 5 1 10 0 83.4kb 41.7kb
green open .kibana_1 tRnqskjwSiuIbDWutnCJAQ 1 1 4 0 28.8kb 14.4kb
green open .monitoring-es-6-2022.02.13 CcOiLXHERS2cJyb_5XfA3Q 1 1 10033 34 11.5mb 5.6mb| 항목 | 설명 |
| health | 인덱스의 상태 |
| status | 인덱스의 사용 여부 |
| index | 인덱스 이름 |
| uuid | 인덱스 uuid |
| pri | 프라이머리 샤드 수 |
| rep | 레플리카 수. 1이면 프라이머리 샤드와는 별도의 복제본이 1개 있다는 의미 |
| docs.count | 저장된 문서 수 |
| docs.deleted | 삭제된 문서 수 |
| store.size | 인덱스의 전체 용량. 프라이머리 샤드와 레플리카 샤드를 모두 포함한 값. |
| pri.store.size | 프라이머리 샤드의 전체 용량 |
샤드의 상태 확인하기
_cat/shards API
❯ curl "localhost:9200/_cat/shards?v"
# (result)
index shard prirep state docs store ip node
books 1 p STARTED 4 12.3kb 192.168.96.2 es02
books 1 r STARTED 4 12.3kb 192.168.96.4 es03
books 4 p STARTED 1 8kb 192.168.96.5 es01
books 4 r STARTED 1 8kb 192.168.96.4 es03
books 3 p STARTED 2 9.4kb 192.168.96.5 es01
books 3 r STARTED 2 9.4kb 192.168.96.4 es03
books 2 r STARTED 3 11.6kb 192.168.96.2 es02
books 2 p STARTED 3 11.6kb 192.168.96.5 es01
books 0 p STARTED 0 261b 192.168.96.2 es02
books 0 r STARTED 0 261b 192.168.96.5 es01| 항목 | 설명 |
| shard | 인덱스의 샤드 번호. 0 부터 시작. |
| prirep | 프라이머리 샤드인지 레플리카 샤드인지 여부 |
| state | 샤드의 상태 |
| docs | 샤드에 저장된 문서 수 |
| store | 샤드의 크기 |
| ip | 샤드가 배치된 노드의 IP |
| node | 샤드가 배치된 노드 |
샤드의 상태
STARTED: 정상 상태INITIALIZING: 샤드 초기화 중인 상태. 최초 배치될 때 혹은 샤드에 문제가 발생하여 새롭게 배치될 때.RELOCATING: 샤드가 현재 노드에서 새로운 노드로 이동하고 있는 상태.UNASSIGNED: 샤드가 어느 노드에도 배치되지 않은 상태
stats API로 지표 확인하기
책의 내용(p.221)을 참고하여 kibana의 Monitoring 메뉴의 메트릭을 살펴본다.
성능 확인과 문제 해결
책의 내용(p.230)을 이해하여 ES의 동작 방식을 이해하도록 한다.
9장. 검색 엔진으로 활용하기
Inverted Index
https://esbook.kimjmin.net/06-text-analysis/6.1-indexing-data
Text Analysis
https://esbook.kimjmin.net/06-text-analysis/6.2-text-analysis
Search API
테스트 데이터 적재
https://github.com/benjamin-btn/ES-SampleData/blob/master/sample09-1.json
{"index":{"_id":"1"}}
{ "title": "ElasticSearch Training Book", "publisher": "insight", "ISBN": "9788966264849", "release_date": "2020/09/30", "description": "ElasticSearch is cool open source search engine" }
{"index":{"_id":"2"}}
{ "title" : "Kubernetes: Up and Running", "publisher": "O'Reilly Media, Inc.", "ISBN": "9781491935675", "release_date": "2017/09/03", "description" : "What separates the traditional enterprise from the likes of Amazon, Netflix, and Etsy? Those companies have refined the art of cloud native development to maintain their competitive edge and stay well ahead of the competition. This practical guide shows Java/JVM developers how to build better software, faster, using Spring Boot, Spring Cloud, and Cloud Foundry." }
{"index":{"_id":"3"}}
{ "title" : "Cloud Native Java", "publisher": "O'Reilly Media, Inc.", "ISBN": "9781449374648", "release_date": "2017/08/04", "description" : "What separates the traditional enterprise from the likes of Amazon, Netflix, and Etsy? Those companies have refined the art of cloud native development to maintain their competitive edge and stay well ahead of the competition. This practical guide shows Java/JVM developers how to build better software, faster, using Spring Boot, Spring Cloud, and Cloud Foundry." }
{"index":{"_id":"4"}}
{ "title" : "Learning Chef", "publisher": "O'Reilly Media, Inc.", "ISBN": "9781491944936", "release_date": "2014/11/08", "description" : "Get a hands-on introduction to the Chef, the configuration management tool for solving operations issues in enterprises large and small. Ideal for developers and sysadmins new to configuration management, this guide shows you to automate the packaging and delivery of applications in your infrastructure. You’ll be able to build (or rebuild) your infrastructure’s application stack in minutes or hours, rather than days or weeks." }
{"index":{"_id":"5"}}
{ "title" : "Elasticsearch Indexing", "publisher": "Packt Publishing", "ISBN": "9781783987023", "release_date": "2015/12/22", "description" : "Improve search experiences with ElasticSearch’s powerful indexing functionality – learn how with this practical ElasticSearch tutorial, packed with tips!" }
{"index":{"_id":"6"}}
{ "title" : "Hadoop: The Definitive Guide, 4th Edition", "publisher": "O'Reilly Media, Inc.", "ISBN": "9781491901632", "release_date": "2015/04/14", "description" : "Get ready to unlock the power of your data. With the fourth edition of this comprehensive guide, you’ll learn how to build and maintain reliable, scalable, distributed systems with Apache Hadoop. This book is ideal for programmers looking to analyze datasets of any size, and for administrators who want to set up and run Hadoop clusters." }
{"index":{"_id":"7"}}
{ "title": "Getting Started with Impala", "publisher": "O'Reilly Media, Inc.", "ISBN": "9781491905777", "release_date": "2014/09/14", "description" : "Learn how to write, tune, and port SQL queries and other statements for a Big Data environment, using Impala—the massively parallel processing SQL query engine for Apache Hadoop. The best practices in this practical guide help you design database schemas that not only interoperate with other Hadoop components, and are convenient for administers to manage and monitor, but also accommodate future expansion in data size and evolution of software capabilities. Ideal for database developers and business analysts, the latest revision covers analytics functions, complex types, incremental statistics, subqueries, and submission to the Apache incubator." }
{"index":{"_id":"8"}}
{ "title": "NGINX High Performance", "publisher": "Packt Publishing", "ISBN": "9781785281839", "release_date": "2015/07/29", "description": "Optimize NGINX for high-performance, scalable web applications" }
{"index":{"_id":"9"}}
{ "title": "Mastering NGINX - Second Edition", "publisher": "Packt Publishing", "ISBN": "9781782173311", "release_date": "2016/07/28", "description": "An in-depth guide to configuring NGINX for your everyday server needs" }
{"index":{"_id":"10"}}
{ "title" : "Linux Kernel Development, Third Edition", "publisher": "Addison-Wesley Professional", "ISBN": "9780672329463", "release_date": "2010/06/09", "description" : "Linux Kernel Development details the design and implementation of the Linux kernel, presenting the content in a manner that is beneficial to those writing and developing kernel code, as well as to programmers seeking to better understand the operating system and become more efficient and productive in their coding." }
{"index":{"_id":"11"}}
{ "title" : "Linux Kernel Development, Second Edition", "publisher": "Sams", "ISBN": "9780672327209", "release_date": "2005/01/01", "description" : "The Linux kernel is one of the most important and far-reaching open-source projects. That is why Novell Press is excited to bring you the second edition of Linux Kernel Development, Robert Love's widely acclaimed insider's look at the Linux kernel. This authoritative, practical guide helps developers better understand the Linux kernel through updated coverage of all the major subsystems as well as new features associated with the Linux 2.6 kernel. You'll be able to take an in-depth look at Linux kernel from both a theoretical and an applied perspective as you cover a wide range of topics, including algorithms, system call interface, paging strategies and kernel synchronization. Get the top information right from the source in Linux Kernel Development." }❯ wget https://raw.githubusercontent.com/benjamin-btn/ES-SampleData/master/sample09-1.json
❯ curl -X POST -H "Content-Type: application/json" --data-binary @sample09-1.json http://localhost:9200/test_data/_doc/_bulk?prettysearch API의 형태
- URI Search
- RequestBody Search
URI Search
/{index_name}/_search?q={field1:value1}
❯ curl -X GET "localhost:9200/test_data/_search?q=title:elasticsearch&pretty"RequestBody Search
/{index_name}/_search
{
"query": {
"term": {
"field1": "value1"
}
}
}
❯ curl -X GET "localhost:9200/test_data/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"term": { "title": "elasticsearch" }
}
}
'RequestBody의 옵션
| 옵션 | 설명 |
| query | 검색을 위한 쿼리문 |
| from/size | 검색 결과를 페이징. 기본값은 from 0, size 10. 예) from:0/size:10, from:11/size:10 |
| sort | 검색 결과를 _score가 아닌 별도의 필드를 기준으로 정렬 |
| source | 검색 결과 중 특정 필드만 조회하도록 지정 |
| highlighting | 검색 결과 중 검색어와 매칭하는 부분을 강조 |
| boost | 검색 결과로 나온 스코어를 변경 |
| scroll | 검색 결과를 페이징. from/size와 유사하지만 scroll id를 통해 다음 번 검색 결과를 가져올 수 있음 |
from/size
- 검색 결과를 페이징한다. 기본값은 from 0, size 10. 예) from:0/size:10, from:11/size:10
❯ curl -X GET "localhost:9200/test_data/_search?pretty" -H 'Content-Type: application/json' -d'
{
"from": 0,
"size": 3,
"query": {
"term": { "publisher": "media" }
}
}
'
# (result)
{
...,
"hits" : {
"total" : 5, # 검색 결과는 5개
"max_score" : 1.0594962,
"hits" : [ # 반환된 결과는 3개
{
"_index" : "test_data",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0594962,
"_source" : {
"title" : "Cloud Native Java",
"publisher" : "O'Reilly Media, Inc.",
...
}
},
{ ... },
{ ... },
]
}
}sort
- 검색 결과를
_score가 아닌 별도의 필드를 기준으로 정렬한다. - analyzed 필드(예: text)를 기준으로 정렬할 수는 없고, not analyzed가 기본인 keyword나 integer 같은 필드를 기준으로 해야 한다.
❯ curl -X GET "localhost:9200/test_data/_search?pretty" -H 'Content-Type: application/json' -d'
{
"sort": [
{ "ISBN.keyword": "desc"}
],
"query": {
"term": { "title": "nginx" }
}
}
'
# (result)
{
...,
"hits" : {
"total" : 2,
...,
"hits" : [
{
...,
"_source" : {
"title" : "NGINX High Performance",
"ISBN" : "9781785281839",
...
},
"sort" : [
"9781785281839"
]
},
{
...,
"_source" : {
"title" : "Mastering NGINX - Second Edition",
"ISBN" : "9781782173311",
...
},
"sort" : [
"9781782173311"
]
}
]
}
}source
- 검색 결과 중 특정 필드만 조회하도록 지정한다.
❯ curl -X GET "localhost:9200/test_data/_search?pretty" -H 'Content-Type: application/json' -d'
{
"_source": ["title", "description"],
"query": {
"term": { "title": "nginx" }
}
}
'
# (result)
{
...,
"hits" : {
"total" : 2,
"max_score" : 1.172009,
"hits" : [
{
...,
"_source" : {
"description" : "An in-depth guide to configuring NGINX for your everyday server needs",
"title" : "Mastering NGINX - Second Edition"
}
},
{
...,
"_source" : {
"description" : "Optimize NGINX for high-performance, scalable web applications",
"title" : "NGINX High Performance"
}
}
]
}
}scroll
- 검색 결과를 페이징하여 조회한다. from/size와 유사하지만 scroll id를 통해 다음 번 검색 결과를 가져올 수 있다.
- 검색 당시의 스냅샷을 기반으로 데이터를 제공한다. scroll id가 유지되는 동안에는 새로운 문서가 색인되어도 검색 결과에 영향을 주지 않는다.
- 최초에는
POST "localhost:9200/test_data/_search?scroll=1m과 body에size를 명시하고 검색한다.scroll:scroll_id(search context)를 유지해야 하는 기간을 지정한다.1m: 1분. (see Time Units)- 이 기간동안 스냅샷을 유지하기 위해 힙 메모리나 세그먼트를 유지해야 하므로 필요한 만큼만 설정해야 한다. OOM이 발생할 수 있다.
- 조회결과의
_scroll_id프로퍼티에scroll_id값이 반환된다.
- 두 번째 부터는
POST "localhost:9200/_search/scroll과 body에scroll,scroll_id를 지정하여 계속 호출하면 다음 페이지를 조회할 수 있다. 이 때 별도의 쿼리는 필요하지 않다. - 끝까지 도달하면 조회 결과가 비어서 반환된다.
scroll파라미터는 더 이상 권장되지 않으며search_after파라미터를 사용하는 것을 권장하고 있으므로, reference document를 반드시 읽고 사용하도록 한다.
❯ curl -X POST "localhost:9200/test_data/_search?scroll=1m&pretty" -H 'Content-Type: application/json' -d'
{
"size": 1,
"_source": ["title", "description"],
"query": {
"match": { "title": "nginx" }
}
}
'
# (result)
{
"_scroll_id" : "DnF1ZXJ5VGhlbkZldGNoAwAAAAAAAB-9FmFqcE1rR3E0UXV1bng4dVR0UlIxdFEAAAAAAAAfvhZhanBNa0dxNFF1dW54OHVUdFJSMXRRAAAAAAAAFMEWSWladWFfcDdUcGEtZGpGYlNXZU9VUQ==",
...,
"hits" : {
"total" : 2,
"max_score" : 1.172009,
"hits" : [
{
...,
"_source" : {
"description" : "An in-depth guide to configuring NGINX for your everyday server needs",
"title" : "Mastering NGINX - Second Edition"
}
}
]
}
}
❯ curl -X POST "localhost:9200/_search/scroll?pretty" -H 'Content-Type: application/json' -d'
{
"scroll": "1m",
"scroll_id": "DnF1ZXJ5VGhlbkZldGNoAwAAAAAAAB-9FmFqcE1rR3E0UXV1bng4dVR0UlIxdFEAAAAAAAAfvhZhanBNa0dxNFF1dW54OHVUdFJSMXRRAAAAAAAAFMEWSWladWFfcDdUcGEtZGpGYlNXZU9VUQ=="
}
'
# (result)
{
"_scroll_id" : "DnF1ZXJ5VGhlbkZldGNoAwAAAAAAAB-9FmFqcE1rR3E0UXV1bng4dVR0UlIxdFEAAAAAAAAfvhZhanBNa0dxNFF1dW54OHVUdFJSMXRRAAAAAAAAFMEWSWladWFfcDdUcGEtZGpGYlNXZU9VUQ==",
...,
"hits" : {
"total" : 2,
"max_score" : 1.172009,
"hits" : [
{
...,
"_source" : {
"description" : "Optimize NGINX for high-performance, scalable web applications",
"title" : "NGINX High Performance"
}
}
]
}
}참고: deep pagination
https://velog.io/@nmrhtn7898/elasticsearch-깊은deep-페이지네이션
Query DSL
검색 쿼리는 Query DSL로 불리며 Query Context와 Filter Context로 분류한다.
Query Context
- Full Text Search(전문 검색)이다.
- analyzer를 활용해서 검색한다. 대소문자를 구별하지 않는다.
- 검색어가 문서와 얼마나 연관이 있는지를 나타내는 score 값을 계산한다.
- 응답속도가 상대적으로 느리다.
- 예) 책을 내용으로 검색.
Filter Context
- 검색어가 문서에 존재하는지 여부를 검사한다(true/false).
- analyzer를 사용하지 않는다. 대소문자를 구별한다.
- score 값을 계산하지 않는다.
- 응답속도가 상대적으로 빠르다.
- 예) 책을 ISBN으로 검색. 직원을 사번으로 검색.
Query Context (=Full Text Query)
- 검색어를 analyze 한다.
주요 Query Context
| 종류 | 설명 |
| match | 검색어를 토크나이징(by analyzer)한 결과인 토큰들이 문서에 존재하는지 여부를 확인한다 |
| match_phrase | match와 비슷하지만 검색어에 입력된 순서를 지켜야 한다 |
| multi_match | match와 동작원리는 같으며, 다수의 필드를 검색하기 위해 사용한다 |
match
- 검색어로 들어온 문자열을 alanyzer를 통해 토큰들로 만들어, 이 토큰들을 가지고 있는 문서를 검색한다.
- 토큰이 가장 많이 포함된 문서를 우선으로 검색 결과를 반환하며, _score 필드를 포함하고 있다.
- 토큰의 순서는 고려하지 않는다.
❯ curl -X POST "localhost:9200/test_data/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"match": { "description": "nginx guide" }
}
}
'
# (result)
{
...,
"hits" : {
"total" : 8, # 총 8개의 문서가 검색됨
"max_score" : 2.5319686,
"hits" : [
{
...,
"_score" : 2.5319686,
"_source" : {
...,
# NGINX, guide를 포함하고 있다. score가 가장 높아 맨 앞에 위치한다.
"description" : "An in-depth guide to configuring NGINX for your everyday server needs"
}
},
{
...,
"_score" : 0.52119774,
"_source" : {
...,
# guide를 포함하고 있다.
"description" : "What separates the traditional enterprise from the likes of Amazon, Netflix, and Etsy? Those companies have refined the art of cloud native development to maintain their competitive edge and stay well ahead of the competition. This practical guide shows Java/JVM developers how to build better software, faster, using Spring Boot, Spring Cloud, and Cloud Foundry."
}
},
{
"...,
"_score" : 0.2876821,
"_source" : {
...,
# NGINX를 포함하고 있다.
"description" : "Optimize NGINX for high-performance, scalable web applications"
}
},
...match_phrase
- match와 유사하지만 토큰의 순서를 정확하게 지켜야 한다.
❯ curl -X POST "localhost:9200/test_data/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"match_phrase": { "description": "Kernel Linux" }
}
}
'
# (result)
{
...,
"hits" : {
"total" : 0, # "Linux Kernel"을 포함하는 문서는 많이 있지만 순서가 맞지 않다.
"max_score" : null,
"hits" : [ ]
}
}multi_match
- match와 동일하지만 두 개 이상의 필드에 match 쿼리를 할 수 있다.
❯ curl -X POST "localhost:9200/test_data/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"multi_match": {
"query": "kernel",
"fields": [ "title", "description" ]
}
}
}
'Filter Context (=Term Level Query)
- 검색어의 포함 여부를 찾는다.
- 검색어를 analyze 하지 않는다. 대소문자를 구별한다.
주요 Filter Context
| 종류 | 설명 |
| term | 검색어로 입력한 단어와 정확하게 일치하는 단어가 있는지 검색한다 |
| terms | term과 유사하지만, 여러 개의 검색어를 기준으로 하나 이상의 단어가 일치하는지 검색한다 |
| range | 특정 값의 범위 안에 있는지 검색한다 |
| wildcard | 와일드카드 패턴에 해당하는 값이 있는지 검색한다 (비추천) |
term
- 정확하게 일치하는 단어를 찾는다.
- 검색어를 analyze를 하지 않는다. 대소문자를 구별한다.
- 따라서 text 타입의 필드를 검색할 때는 소문자로 검색하던지, match 쿼리를 사용해야 한다.
❯ curl -X POST "localhost:9200/test_data/_search?pretty" -H 'Content-Type: application/json' -d'
{
"filter": {
"term": { "ISBN": "9781491901632" }
}
}
'
# (result)
{
...,
"hits" : {
"total" : 1,
"hits" : [
{
...
},range
❯ curl -X POST "localhost:9200/test_data/_search?pretty" -H 'Content-Type: application/json' -d'
{
"filter": {
"range": {
"release_date": {
"gte": "2015/01/01",
"lte": "2015/12/31"
}
}
}
}
'bool query를 이용해 쿼리 조합하기
bool query를 이용하면 Query Context와 Filter Context를 조합해서 사용할 수 있다.
주요 bool query
| 항목 | 설명 | 스코어링 | 캐싱 | Query Context |
| must | 항목 내 쿼리에 일치하는 문서를 검색 | O | X | Query Context |
| should | 항목 내 쿼리에 일치하는 문서를 검색 | O | X | Query Context |
| filter | 항목 내 쿼리에 일치하는 문서를 검색 | X | O | Filter Context |
| must_not | 항목 내 쿼리에 일치하지 않는 문서를 검색 | X | O | Filter Context |
- 일반적인 로직에서 값을 조회할 때는
score를 계산하지 않는filter를 사용하면 된다. - Full Text Search를 사용해야 할 때는
score를 계산하는must를 사용하면 된다.
Query Context와 Filter Context를 조합하기
❯ curl -X POST "localhost:9200/test_data/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "nginx"
}
}
],
"filter": [
{
"range": {
"release_date": {
"gte": "2016/01/01",
"lte": "2017/12/31"
}
}
}
]
}
}
}
'term 쿼리 여러 개를 조합하기
bool 하위에 filter를 배열로 지정하면 AND 조건으로 묶인 쿼리가 된다.
❯ curl -X POST "localhost:9200/test_data/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"bool": {
"filter": [
{
"term": {
"ISBN": "9781785281839"
}
},
{
"term": {
"release_date": "2015/07/29"
}
}
]
}
}
}
'
# (result)
{
"hits" : {
"total" : 1,
"hits" : [
{
"_source" : {
"title" : "NGINX High Performance",
"publisher" : "Packt Publishing",
"ISBN" : "9781785281839",
"release_date" : "2015/07/29",
"description" : "Optimize NGINX for high-performance, scalable web applications"
}
}
]
}
}
❯ curl -X POST "localhost:9200/test_data/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"bool": {
"filter": [
{
"term": {
"ISBN": "9781785281839"
}
},
{
"range": {
"release_date": {
"gte": "2015/01/01",
"lte": "2015/12/31"
}
}
}
]
}
}
}
'
# (결과 동일)나머지 내용은 책을 참고하세요.
- 10장. 색인 성능 최적화
- 11장. 검색 성능 최적화
- 12장. ElasticSearch 클러스터 구축 시나리오
(End)
'잡다구리' 카테고리의 다른 글
| jpa: 컬럼의 네이밍 컨벤션 전략 - physical-strategy (0) | 2022.08.16 |
|---|---|
| Spring: @DataJpaTest (0) | 2022.08.14 |
| Validation with Spring Boot - the Complete Guide (0) | 2022.08.14 |
| Spring: @ConfigurationProperties (0) | 2022.08.14 |
| Hexagonal Architecture with Java and Spring (0) | 2022.08.13 |
| Building a Multi-Module Spring Boot Application with Gradle (0) | 2022.08.13 |
| What is Upstream and Downstream in Software Development (0) | 2022.08.13 |
| reactor: Handle (0) | 2022.08.13 |




댓글